
Инструментарий для извлечения данных из дампов трафика, обучения модели и тестирования работы метода опубликован на GitHub. Возможность проведения атаки продемонстрирована для 28 популярных больших языковых моделей от крупнейших производителей. Например, точность определения запросов на тему «отмывание денег» для многих AI-сервисов составила 100%, при наличии в анализируемом трафике 1 искомого запроса и 10000 запросов, не связанных с нужной темой.
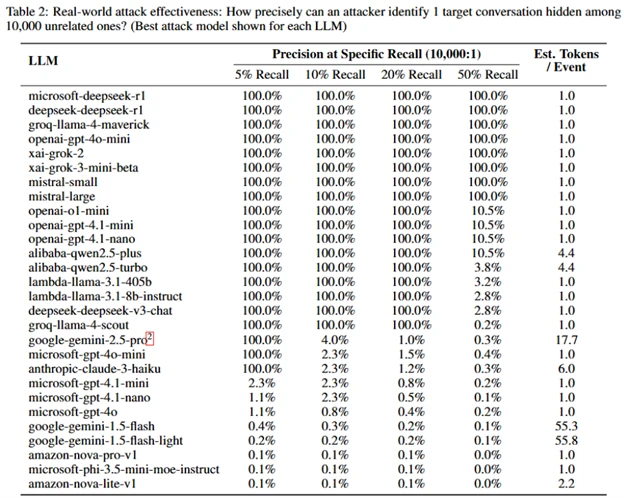
Причиной утечки информации является то, что модели генерируют ответ на запрос пошагово, по одному токену за раз, на каждом шагу используя предыдущий токен в качестве контекста для определения следующего наиболее вероятного слова или фразы. Соответственно, на каждый токен отправляется отдельный сетевой пакет и задержка между пакетами соответствует задержке между определением моделью следующего токена.
В TLS, если не используется сжатие данных, размен шифротекста равен размеру незашифрованного текста плюс константа. При создании модели, сопоставляющей искомые наборы токенов с размером пакетов и задержками между их отправкой, можно достаточно точно определить наличие в трафике искомых тем. В ходе исследования подготовлено три варианта подобных моделей машинного обучения, основанных на архитектурах нейронных сетей LightGBM, Bi-LSTM и BERT. Для каждой модели проведены эксперименты по определению искомой темы при анализе только размера пакетов, только задержек между пакетами и обеих критериев.
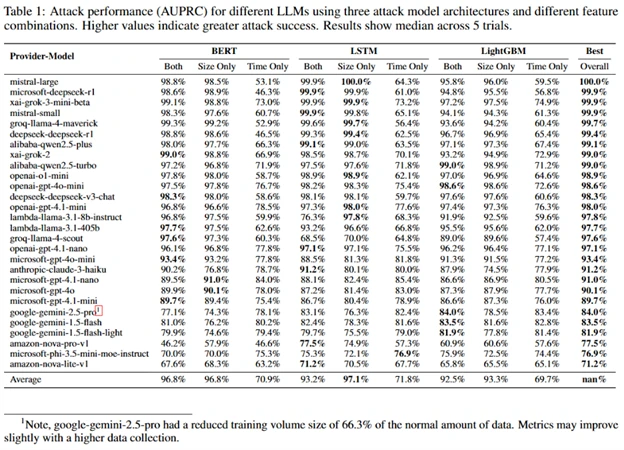
Для снижения эффективности пассивного анализа тематики запросов разработчикам AI-сервисов предложено прикреплять случайное добавочное заполнение, буферизировать передачу токенов или выполнять подстановку фиктивных пакетов.
Источник: http://www.opennet.ru/opennews/art.shtml?num=64218