
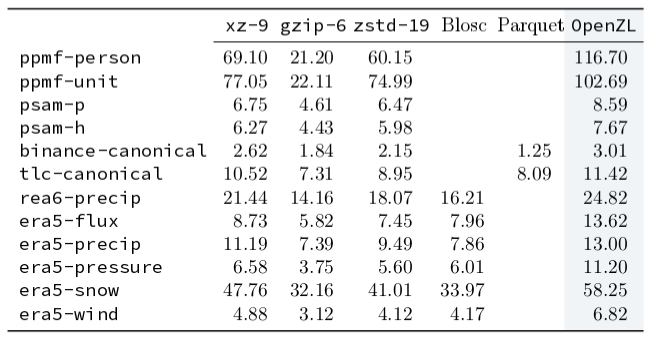
При сжатии БД с астрономическим каталогом звёзд SAO, инструментарий OpenZL позволил сократить размер данных в 2.06 раза, в то время как алгоритм zstd сжал информацию в 1.31 раза, а XZ в 1.64 раза. При этом по скорости сжатия OpenZL опередил zstd в два раза (203 MB/s против 115 MB/s), а XZ — в 65 раз (203 MB/s против 3.1 MB/s). Распаковка в OpenZL оказалась незначительно медленнее zstd (822 MB/s против 890 MB/s) и в 27 быстрее XZ.
OpenZL не является алгоритмом общего назначения и показывает хорошие результаты только для данных с заранее известной структурой.
Работа OpenZL сводится к адаптивной генерации упаковщика на основе переданного описания данных. В результате формируется код для сжатия, оптимизированный для конкретного формата данных. Для распаковки применяется универсальный распаковщик, совместимый со всеми генерируемыми упаковщиками.
Упаковка и распаковка осуществляется при помощи одной утилиты «zli» или библиотеки libopenzl. Структура данных описывается в виде профилей. В состав уже входит набор предопределённых профилей, описывающих типовые форматы хранения. Например, профиль для формата CSV или данных, хранимых в форме массива 64-разрядных чисел. Сжатия сводится к выбору профиля командой «zli list-profiles» и запуску процесса упаковки командой «zli compress —profile имя_профиля». Для распаковки достаточно запустить «zli decompress».
Для специфичных форматов требуется сформировать собственный профиль, используя команду «zli train», которая выявляет закономерности в данных и формирует профиль с оптимальным уровнем сжатия. Используя опцию «—pareto-frontier» созданный профиль можно модернизировать в сторону ускорения упаковки или распаковки, ценой снижения уровня сжатия. Для описания сложных форматов со вложенными структурами и определения раскладки форматов данных в структурах может применяться язык SDDL (Simple Data Description Language).
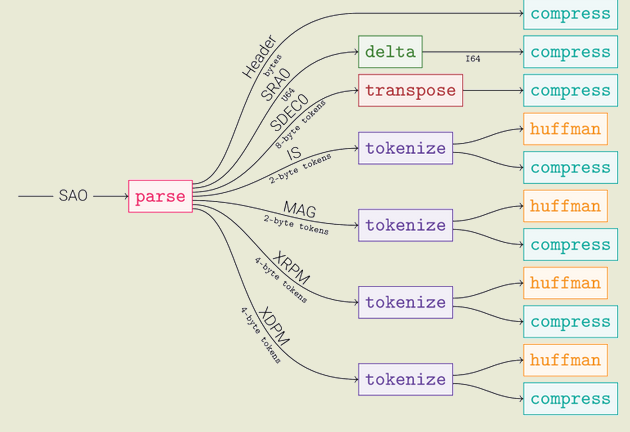
Метод создания оптимальный упаковщиков основан на применении набора примитивных кодировщиков, каждый из которых наиболее эффективен для отдельных типов и последовательностей данных. Для сжатия формируется ориентированный ациклический граф обработки данных, узлами которого являются кодеки, а рёбрами — варианты данных в обрабатываемом формате. В зависимости от поступающего на вход типа данных выбирается цепочка кодеков, оптимально сжимающих поступивший элемент данных. При подобной организации заголовок файла сжимается одним кодеком, поле с целочисленными данными — вторым, поле с увеличивающимся счётчиком — третьим, а поле со строковыми данными — четвёртым.
Источник: http://www.opennet.ru/opennews/art.shtml?num=64019