
В ходе изучения публично доступных поддоменов deepseek.com исследователи обратили внимание на хосты оoauth2callback.deepseek.com и dev.deepseek.com, на сетевых портах 9000 и 8123 которых находился сервис хранения, основанный на СУБД ClickHouse. Сетевой порт 9000 использовался для подключения приложений, а через порт 8123 предоставлялся web-интерфейс, дающий возможность отправить любой SQL-запрос.
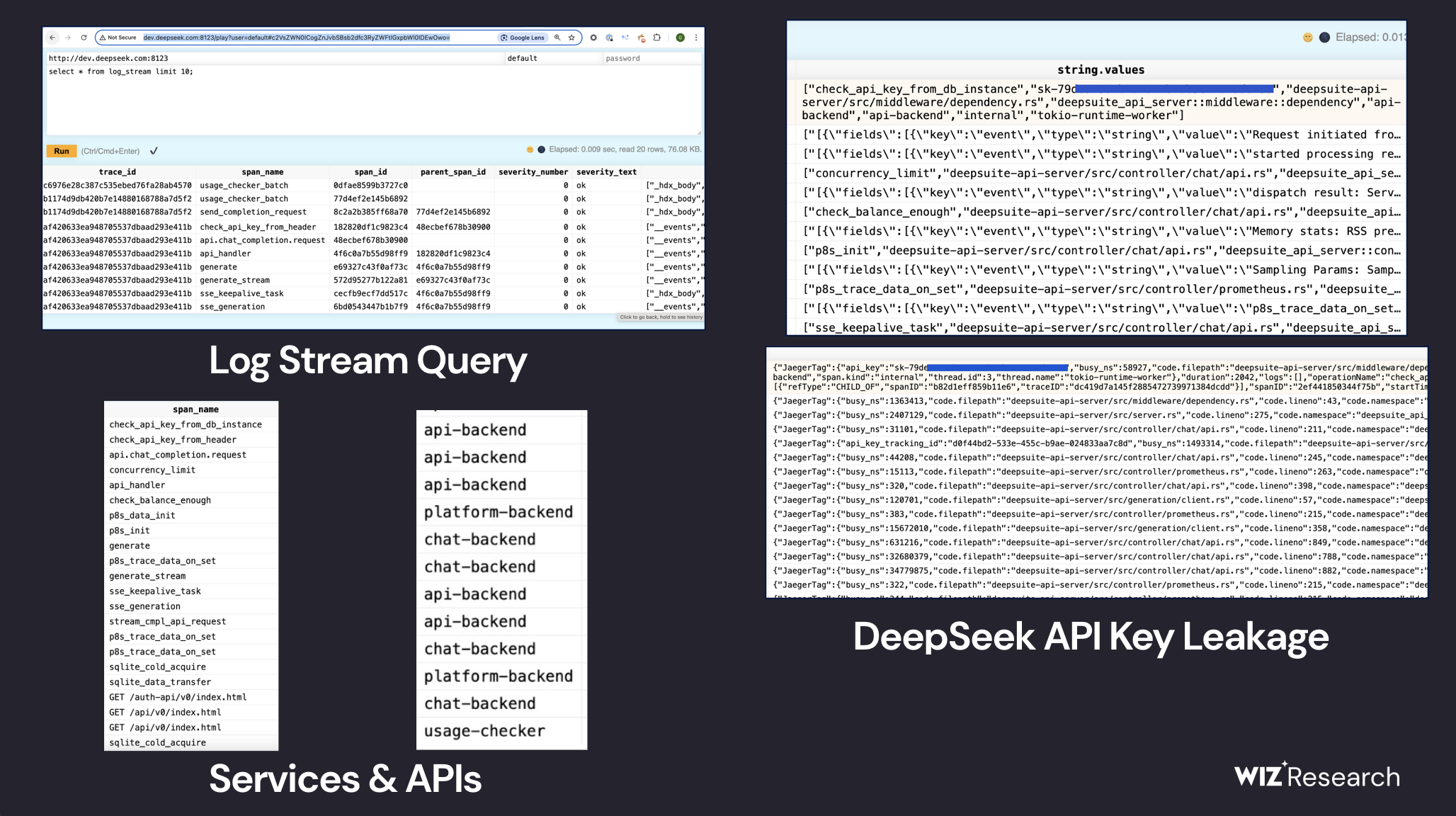
Выставленные настройки СУБД предоставляли полный контроль над операциями в БД, при доступе без прохождения аутентификации. По мнению исследователей, имеющегося доступа было достаточно для организации атаки, не ограничивающейся СУБД и позволяющей получить привилегированный доступ к инфраструктуре DeepSeek.
Напомним, что на прошлой неделе компания DeepSeek опубликовала под свободной лицензией MIT большие языковые модели DeepSeek-R1 и DeepSeek-R1-Zero, охватывающие 671 миллиард параметров. DeepSeek-R1 рассматривается как самая крупная и качественная модель для решения задач, требующих логического вывода, опубликованная в открытом доступе. В 12 проведённых тестах указанная модель обогнала проприетарные модели Claude-3.5-Sonnet, OpenAI GPT-4o и OpenAI o1, а в 9 тестах продемонстрировала близкие показатели.
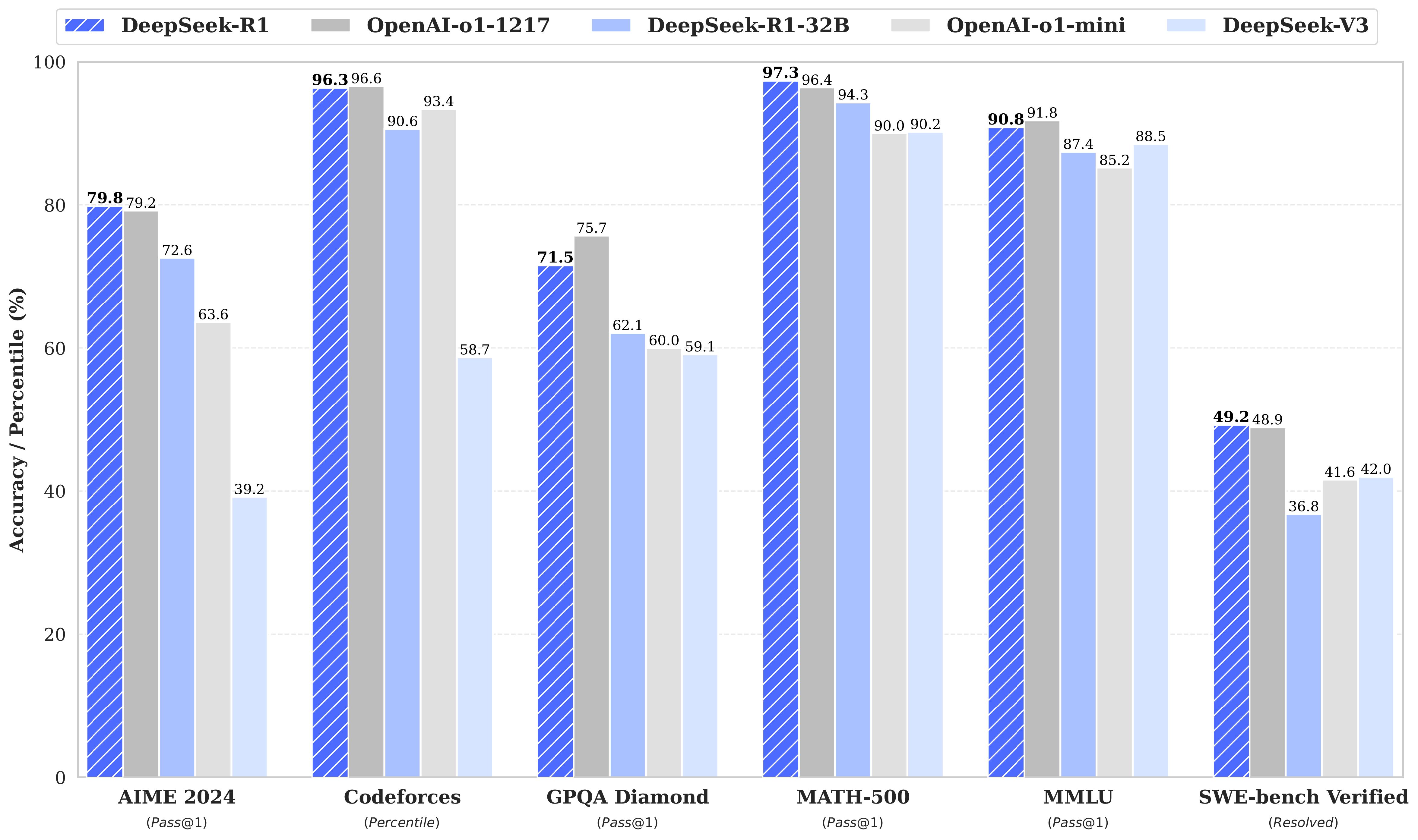
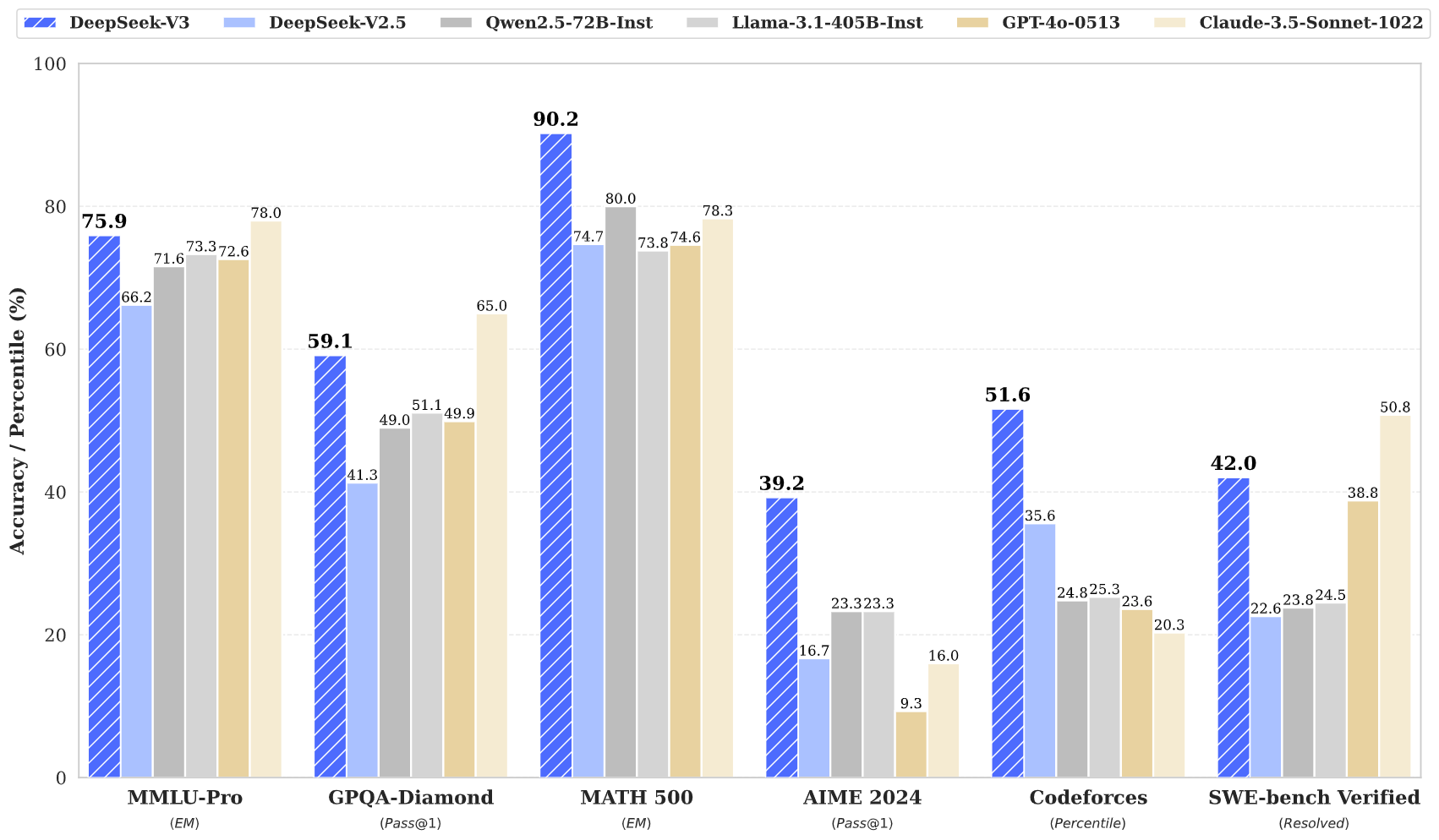
DeepSeek-R1 является улучшенным вариантом языковой модели DeepSeek-V3, опубликованной в декабре 2024 года под лицензией MIT. Модель DeepSeek-V3, как и DeepSeek-R1, охватывает 671 миллиард параметров, учитывает контекст в 128 тысяч токенов и по своим характеристикам близка или обгоняет Claude-3.5-Sonnet и GPT-4o. DeepSeek-V3 и DeepSeek-R1 могут запускаться на собственном оборудовании при помощи типовых открытых фреймворков для выполнения языковых моделей, таких как
vLLM, TensorRT-LLM, LMDeploy и SGLang. Модели подходят для создания диалоговых систем, виртуальных ассистентов, генерации текста, формирования ответов на вопросы, краткого изложения и обобщения содержимого, объяснения сути концепций и терминов.
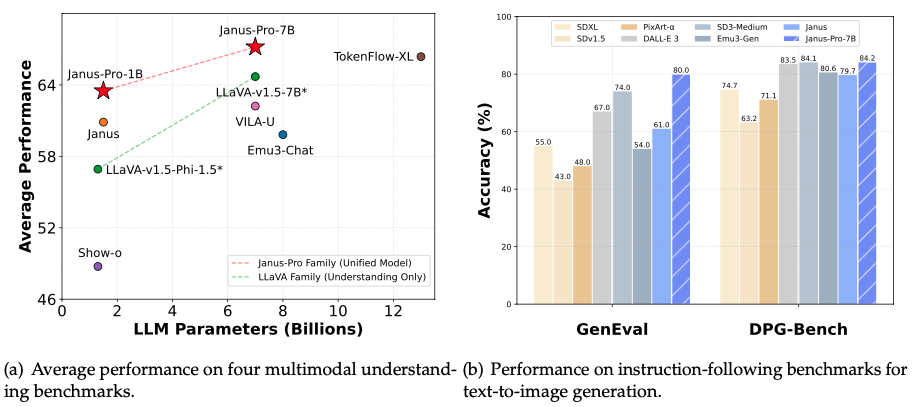
Помимо DeepSeek-R1 и DeepSeek-V3 компания также развивает открытые мультимодальные модели Janus, способные обрабатывать, понимать и генерировать графические изображения и звуковые данные. Последняя модель Janus Pro близка по характеристикам к модели DALL-E 3 от компании OpenAI при решении задач по генерации изображений по текстовому описанию.
Заявлено, что для обучения модели DeepSeek-V3 было использовано 2048 видеокарт NVIDIA TESLA H800, а затраты на обучение составили 5.58 млн долларов. Для сравнения затраты на обучение модели GPT-4 оцениваются в 80-100 млн долларов. Подобная разница привела к обвалу стоимости акций многих компаний, связанных с AI (например, стоимость акций NVIDIA снизилась на 17%), и возникновению домыслов, что DeepSeek скрывает реальные затраты. Компания OpenAI упомянула, что получила доказательство того, что в процессе обучения моделей DeepSeek были задействованы проприетарные модели OpenAI, что нарушает правила сервисов OpenAI, запрещающих использование вывода моделей OpenAI при разработке продуктов, конкурирующих с OpenAI (примечательно, что в своё время к OpenAI предъявляли претензии из-за использования при обучении моделей данных, полученных без разрешения).
Источник: http://www.opennet.ru/opennews/art.shtml?num=62639