
Модель Grok предварительно обучена на большой коллекции текстовых данных, используя разработанный в xAI собственный стек обучения, и охватывает около 314 миллиардов параметров, что делает её крупнейшей из доступных открытых больших языковых моделей. Для сравнения недавно открытая Google модель Gemma насчитывает 7 млрд параметров, Meta LLaMA — 65 млрд параметров, Yandex YaLM — 100 млрд, OpenAI GPT-3.5 — 175 млрд, а лидер рынка, модель GPT-4, предположительно включает 1.76 триллиона параметров.
Открытый вариант модели Grok-1 опубликован в базовом представлении и не включает оптимизаций для определённых областей использования, таких как организация диалоговых систем. Для тестирования требуется GPU c большим объёмом памяти (каким именно не уточняется).
В открытом доступе размещён статичный слепок модели, в то время как одной из особенностей развиваемого для Twitter-а чатбота Grok является динамическая адаптация к появляющемуся новому содержимому (для доступа к новым знаниям используется интеграция с платформой X/Twitter).
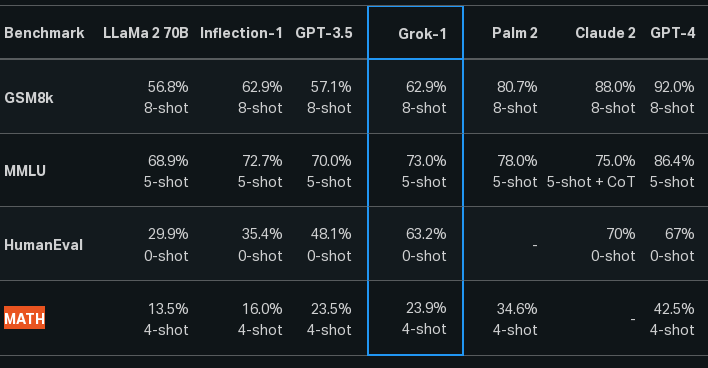
Построенный на базе Grok чатбот опережает GPT-3.5 в тестах на решение математических задач средней школы (GSM8k), формирование ответов на междисциплинарные вопросы (MMLU), дополнение кода на языке Python (HumanEval) и решение вузовских математических задач, описанных в формате LaTeX (MATH).
Источник: http://www.opennet.ru/opennews/art.shtml?num=60801